In recent years, large language models (LLMs) have emerged as powerful tools capable of understanding and generating human-like text across a variety of domains. These models have also given rise to a new class of tools known as AI agents: systems that leverage the capabilities of LLMs to autonomously perform tasks, often with little to no human intervention. Among these, AI coding agents are a particularly exciting development for, as the name might imply, coders. These agents are designed specifically to assist with development by generating, modifying, and executing code, managing files, and even writing git commit messages.
Most discussions around AI coding agents focus heavily on software engineering and web development. There is a noticeable gap when it comes to their application in the data field. Perhaps this is due to the inherently less visual nature of data science—working with models and data pipelines doesn’t produce the immediate visual feedback of a web interface, making the results less “flashy” by comparison. Yet, the potential impact of AI coding agents in data science is just as significant.
As a data professional myself, I was curious to see how well an AI coding agent could support the workflow of a typical data science proof of concept. To explore this, I conducted a hands-on evaluation using Cursor, an IDE with an AI coding assistant that integrates with your development environment. I’ve had a bit of experience with Cursor ‘ vibe-coding’ a website in my free time (honestly who doesn’t). But I am no web developer, so I could not really determine how well it was doing the job, just that it worked. So I was curious to apply it in an area where I am very familiar with all concepts and best practices.
The initial setup: from MNIST to the unknown
I applied it to two short proof of concepts: one based on the classic MNIST dataset for digit recognition, and another involving a semi-randomly generated dataset. While MNIST serves as a convenient benchmark for quickly building a data science proof of concept due to its popularity and extensive documentation, my real interest lay in seeing how the agent would perform on a less conventional dataset. One for which it had no prior ‘knowledge’ or readily available examples to draw from.
I began with a simple and clear scope: for each project, I wanted to explore the data through basic analysis and visualizations, train a model, and make predictions on new data. I deliberately skipped the data cleaning phase, as both datasets were already in good enough condition, and because it typically requires business-specific context on how to clean it, which both of these projects lacked. The implementation was to be done in Python, relying on the standard data science stack along with Streamlit and Plotly for visualizations.
Fast start with MNIST: clean code, but messy versions
My first interaction with the ai coding agent involved setting up the project structure. I provided a description of the scope and asked the agent to generate an appropriate folder and file layout to support it. It did just that along with a requirements.txt file (which is a list of the Python packages needed to run the project). However, a significant issue emerged almost immediately: the version numbers it listed in the file were outdated, sometimes by years. For example, it suggested numpy==1.24.0, a release from December 2022. Even after prompting it multiple times to fetch the latest stable versions, including one using Cursor’s web search integration, some packages remained outdated. Ultimately, I had to update these manually. A minor inconvenience, but still a shame given the capabilities of the agent.
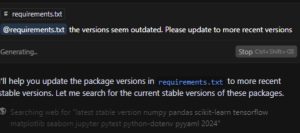
Figure 1: The Agent struggles with finding the right stable versions, even while using web search.
Once the initial folder and file structure was set up, I moved on to actual code generation, starting with the MNIST project. The visualization dashboard, built with Streamlit and Plotly, came together remarkably quickly. The agent produced a functioning dashboard from the initial prompt, which I then refined over the course of several iterations. Normally, I spend a considerable amount of time fine-tuning visual elements. In this case, I could simply describe the desired adjustments, and the agent would implement them almost instantly. This responsiveness was both satisfying and a major time-saver.
Training the model for MNIST went just as smoothly. The agent recommended a small Convolutional Neural Network using TensorFlow, and the architecture it generated (three convolutional blocks followed by two dense layers) was appropriate for the input size and task. The training process ran without issues, metrics were logged, and the model was saved to a predesignated directory. To take things a step further, I wanted to be able to draw my own digits and classify them live. Adding a drawing canvas to Streamlit took several prompts, but within 15 minutes, the feature was functional. Altogether, I had a working prototype in just a few hours.

Figure 2: Drawing canvas to classify digits with a trained CNN model
Strong performance on new data
Of course, success with MNIST was somewhat expected due to the extensive documentation and examples available online. The real test came with the second, less familiar dataset. My typical approach to exploring such a dataset starts in a Jupyter notebook, where I can iteratively run and inspect code. Unfortunately, Cursor lacked support for notebook generation during the testing and writing of this blog (which was at the end of May). The release of early June does contain this feature, but I was not able to test it thoroughly yet.
Instead of using a Jupyter notebook, I reverted to using Streamlit once more to explore the dataset. With just two prompts, Cursor produced a dashboard that allowed me to review datatypes, check for missing or duplicate values, inspect feature ranges, and visualize distributions. This proved highly effective for assessing data quality, but further data exploration had to be done by both generating extra code for the analysis as well as updating the streamlit app, which felt like overkill, even if I did not have to write the code myself.
I then asked the agent to write code to train a Random Forest Classifier using scikit-learn. It did so accurately, but even though the hyperparameters were explicitly written, they all used the default values. When I inquired about this, the agent proposed adding a grid search implementation to optimize the hyperparameters. This level of foresight was encouraging, as this had anticipated what I would ask for it to do in my next prompt.
After training the model, its performance was quite modest, which was understandable given it was on a synthetic dataset. Finally, I requested code to classify new data and display results on the dashboard. This, too, was handled quickly and effectively.
Lessons learned: getting the most from AI agents
Having completed both projects, I want to share my perspective on how well AI coding agents (Cursor in particular) work in a data science context. In short, they are incredibly helpful for accelerating the coding process, but they are not a replacement for critical thinking and decision-making. You, the data professional, must remain in control of key decisions: which libraries to use (and in what versions), what models to try, and how to interpret or adjust hyperparameters. The agent excels at producing syntactically correct, runnable code quickly, but only when the context is clear and the instructions are explicit.
Ambiguity can lead to erratic behavior. For instance, while I was using Polars throughout a project, the agent suddenly switched to Pandas without any prompt or notification. Fortunately, it switched back immediately when asked. This illustrates the importance of specifying exactly which tools and frameworks to use in each prompt, including which files to modify and how.
It’s also important to recognize the limitations. In my case, it would have been much faster to set up a virtual environment and manually generate the required dependencies than to go back and forth trying to get the agent to update outdated packages. Similarly, the inability to work with Jupyter notebooks was a significant drawback for exploratory tasks.
One highly effective feature that I did not mention yet was Cursor’s autocomplete. In the few instances where I was refactoring code myself, I found myself simply pressing “tab” as it completed multi-line blocks of code accurately and intuitively. Additionally, while the automatically generated git commit messages were a little too verbose for my taste, they did a good job of reflecting the full scope of each commit’s changes in a structured way.
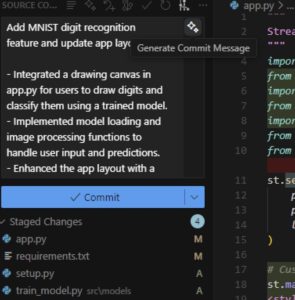
Figure 3: Example of a generated git commit message.
My advice to other data professionals using AI coding agents is to begin where you typically start a project: by thinking critically about the project’s goals and corresponding tools, packages and architecture. Then, communicate the high-level structure to the agent and ask it to propose a file layout. From there, proceed step-by-step. Resist the temptation to generate everything in one go. Work in small increments, just as you would in a manual coding workflow. After each segment, review and test thoroughly before continuing. And when switching to a new phase (say, from visualization to model training) it helps to start a new chat session for clarity and context separation.
Wrapping up: AI Agents in Data Science are promising, but not perfect
To wrap up, I remain optimistic about the potential of AI coding agents in data science. Their speed in generating code and interpreting structured prompts makes them excellent tools for prototyping and quick iteration. However, prompts that were not completely or clearly written sometimes led to unexpected or erratic behavior. Additionally, I did miss support for Jupyter notebooks (though this feature is available now). Another limitation I encountered was outdated package versioning. These limitations highlight that the technology still requires manual oversight and that users must have the expertise to identify and resolve problems.
Lastly, I wasn’t able to test these agents’ reliability on long-term or complex projects. I’m particularly interested to see how they perform on larger, multi-week endeavors. If those experiments prove promising, I plan to share the results in a follow-up blog post in the coming months.